Raksha-Risk
Advanced data modeling to forecast credit risk and flag unusual financial behavior, enabling smarter, timely risk interventions.

Advanced data modeling to forecast credit risk and flag unusual financial behavior, enabling smarter, timely risk interventions.
Developed an AI-powered platform for detecting financial anomalies and assessing credit default risk using real-world transaction and customer data. By integrating behavioral patterns, transactional signals, and account profiles, RakshaRisk delivers predictive insights to support fraud detection, compliance, and proactive risk management strategies.
Financial institutions face growing challenges in detecting fraudulent transactions and assessing credit risk, as traditional systems struggle with imbalanced data and limited transparency. This project unifies anomaly detection and credit default prediction into a single AI-driven solution, ensuring accuracy, speed, and interpretability for smarter, more reliable decision-making.
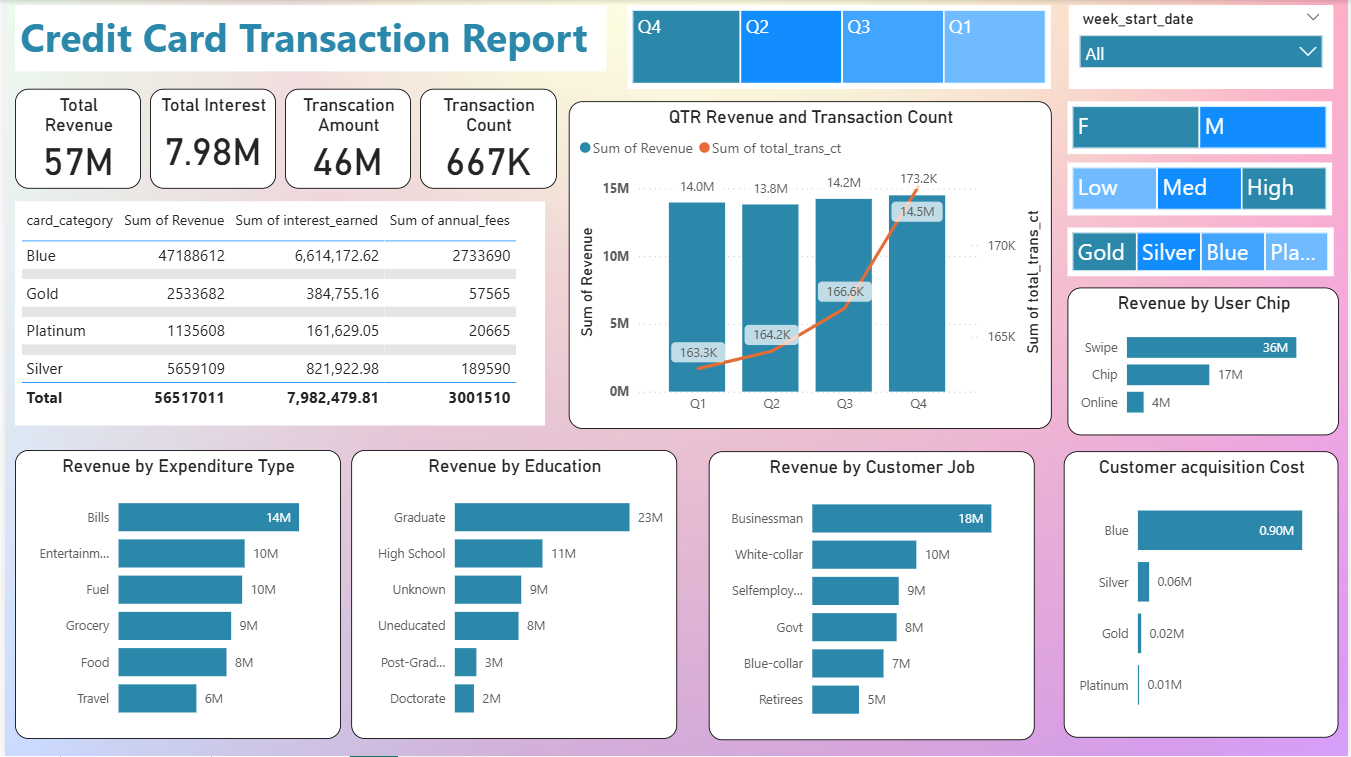
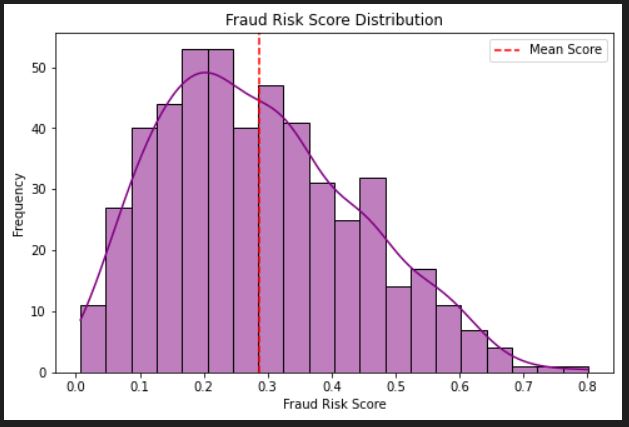
RakshaRisk is all about helping financial institutions stay one step ahead by spotting unusual credit card transactions that might be fraudulent, using smart unsupervised learning methods like Isolation Forest and LOF. At the same time, it predicts which customers might struggle to repay their loans with trusted models like Random Forest and Logistic Regression. What makes it really useful is how it brings all this complex information together into easy-to-understand, interactive dashboards, complete with clear explanations, so decision-makers can confidently take action and protect both their business and customers.
A custom data pipeline was developed to clean, merge, and preprocess these datasets, addressing class imbalance, scaling features, and preparing them for both anomaly detection and classification models.
The data pipeline streamlined the process from raw data ingestion to model-ready datasets, ensuring compatibility for both anomaly detection and supervised classification models.
Click a tab to explore insights:

Daily Energy Demand: Usage peaked during the first week of July.
| Category | Details |
|---|---|
| Programming Languages | Python (scikit-learn, pandas, NumPy) |
| Data Engineering | Custom ETL pipelines, data cleaning, class balancing (SMOTE) |
| Data Analysis | Exploratory Data Analysis (EDA), correlation analysis, feature engineering |
| Modeling | Isolation Forest, Local Outlier Factor, Random Forest, Logistic Regression |
| Visualization | Matplotlib anomaly plots, Power BI dashboards |
| Tools & Libraries | scikit-learn, pandas, NumPy, matplotlib, SHAP, Power BI |
Powered by advanced AI risk intelligence, financial institutions can now uncover hidden anomalies with greater accuracy, anticipate credit defaults earlier, and strengthen the stability and trust of the entire financial ecosystem.